
The Art of Vibe-Crashing
One of the components that surprised me the most during the development of Artiphishell was something we called (for lack of a better name at that time) “DiscoveryGuy”. This was our attempt at building a purely LLM-driven bug-hunting engine for both C and Java, since most of the work at that time was basically to use LLM to aid fuzzing. What caught me off guard was how little effort it actually took to put the first version together (~3 months), yet the results it produced were far beyond what I had initially expected.
The idea was nothing revolutionary: take a function flagged as potentially vulnerable by a quick static pass (e.g., CodeQL or Semgrep), and then let the LLM generate a Python script capable of producing a seed that would crash the program at that exact location.
You have probably already heard this idea dozens of times if you are following research in this area.

The design of DiscoveryGuy was so simple—and frankly a bit counter-intuitive—that almost nobody believed in it at first (including our epic advisors Giovanni Vigna & Chris Kruegel). But skepticism turned into surprise once we demonstrated that it could single-handedly uncover all of the artificial Challenge Problem Vulnerabilities (CPVs) injected in the nginx challenge, as well as many others that popped up during DARPA’s test exhibitions.
So, what’s the “secret sauce” behind DiscoveryGuy? As my teammate @1chig0 likes to put it: “just grep.”
At its core, DiscoveryGuy is built around three components:
- Harness Selection
- Vulnerability Reasoning
- Seed Generation
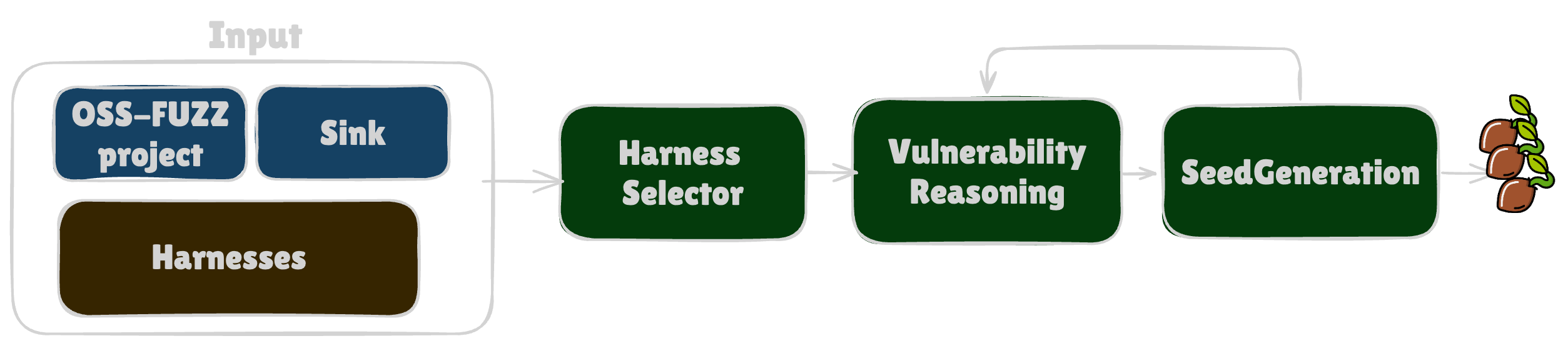
[1] 🤔 Harness Selection
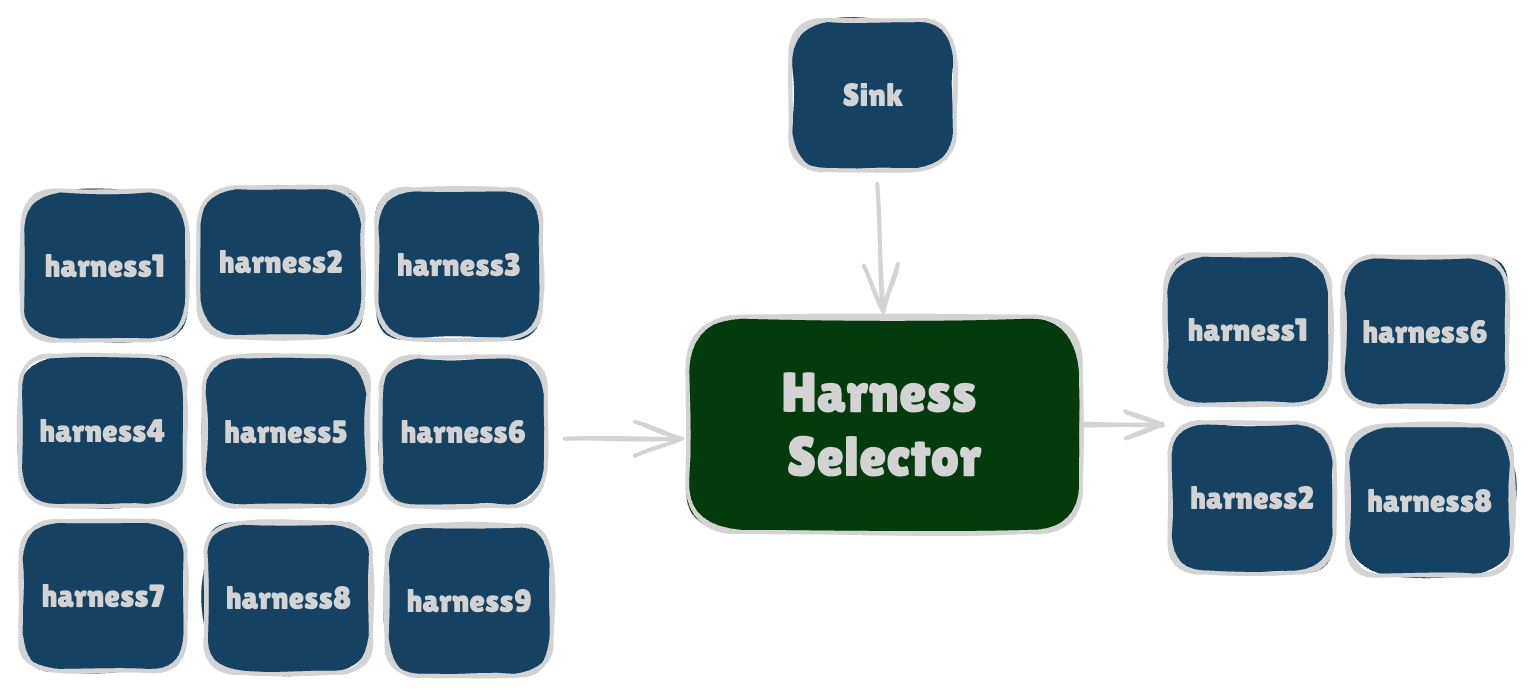
This step is necessary when the call graph generated for the challenge doesn’t clearly indicate which harnesses are actually in scope given a sink (i.e. a vulnerable function like system).
In other words, for a given potentially vulnerable sink, there may be too many candidate harnesses due to over-approximation
(e.g., the curl project has 18 harnesses at the time of writing).
The harness selection step helps narrow down the possibilities to the harnesses most likely to succeed, avoiding unnecessary resource consumptions.
Practically, this is simply implemented by asking an agent, “What are the most likely harnesses that can reach this function in the project?” and by providing the harnesses’ code themselves.
Now you might wonder: “Aren’t there more principled ways to figure out which harnesses are in scope for a given sink?” The answer is: I’m sure yes, but why bother when a simple LLM-based technique worked so well? In our experiments, the correct harness (the one actually needed to reach and trigger the bug) consistently appeared in the top 3. To play it safe, we asked the agent for its top 5 most likely harnesses and carried those forward.
🐾 Follow the code here
💬 See the prompts for this agent here and here
[2] 💭 Vulnerability Reasoning

This is more or less where the magic happens.
We discovered that Anthropic’s models (Claude-4-Sonnet and Opus) were exceptionally good at spotting vulnerable code and outlining the steps needed to generate an input that could crash a target location.
The models only needed a single tool to work effectively.
The ability to grep through the codebase.
Literally just that (combined with some basic context trimming and string manipulation) and the agent (affectionately named JimmyPwn after @1chig0) could reason through complex state machines to trigger non-trivial bugs such as a deserialization RCE in a Jenkins plugin!
🐾 Follow the code here
💬 See the prompts for this agent here and here
[3] 🌱 Seed Generation

The third step—after JimmyPwn has created a “plan for exploitation”—is to generate a Python script that follows the plan and produces a seed.
This part is straightforward: A classic feedback loop to verify that the script works and the seed actually crashes the challenge.
Notably, we consistently saw better results when the vulnerability reasoning was handled by an Anthropic model while the seed generation was done by an OpenAI model (i.e., O3).
No hard proof here, but in practice, that combination just seemed to work better.
🐾 Follow the code here
💬 See the prompts for this agent here and here
Finally, steps 2 and 3 form a feedback loop of their own: the script generation agent can report back to JimmyPwn why a script failed, helping refine the reasoning and ultimately improve the generated scripts. During the finals, we noticed that it occasionally took a couple of iterations to land on a seed that actually triggered a crash.
[4]⚡️ Last step: Fuzz!
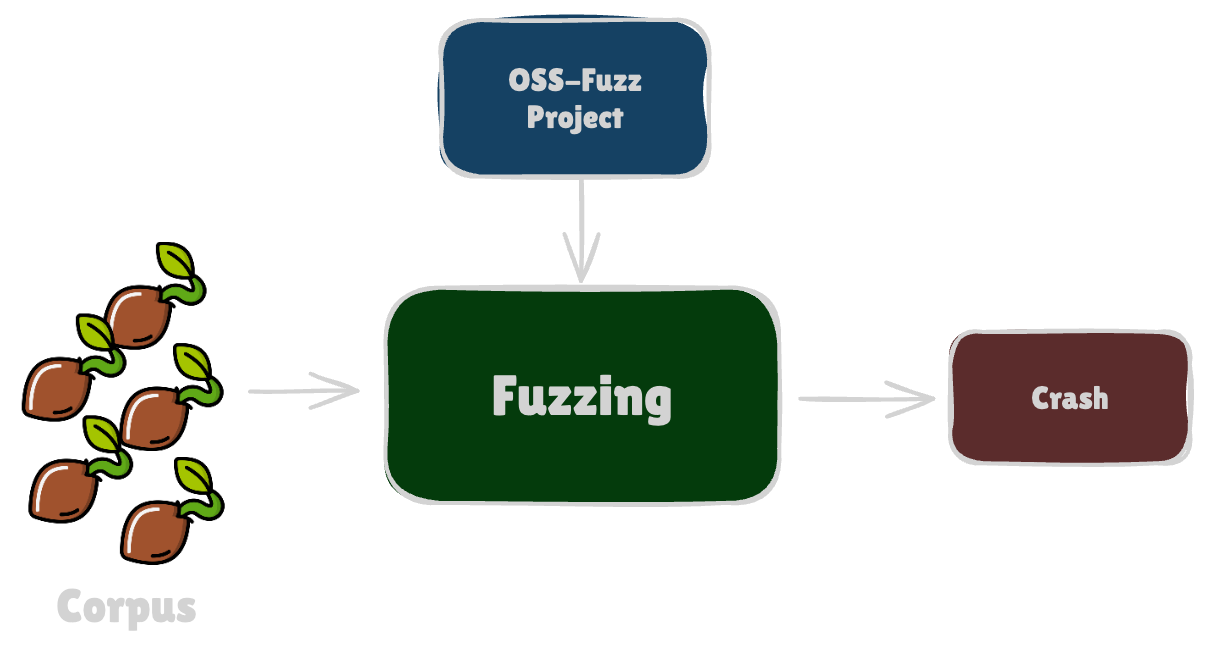
Of course, DiscoveryGuy wasn’t perfect. Sometimes it would generate seeds that came close to the actual crashing input… but not quite. The logical next step was to toss them into the fuzzing queues and let mutations handle the rest. For example, a classic fuzzing setup could take hours to trigger the inserted bug for libpng (https://github.com/aixcc-finals/example-libpng/tree/challenges/delta-scan). But as soon as a DiscoveryGuy seed hit the queue: bam, the crash popped up in seconds.
🐾 Follow the code here
Conclusion
The first time DiscoveryGuy truly blew me away was when the system independently generated a crashing seed for the aforementioned Jenkins email-plugin vulnerability. This is something that our Java fuzzers were able to trigger once in a blue moon, and would have easily taken me several hours to figure out on my own. I truly think that was when I had my “AI moment” and understood that the way vulnerability research will be done is going to change drastically in the next few years.
During the AIxCC finals, the system really delivered: It one-shot 20 different targets (i.e., DiscoveryGuy directly synthesized the crashing seed) and also produced a high-quality corpus for fuzzing. I believe this synergy between DiscoveryGuy and our fuzzing setup is what saved the day, especially given the hiccups in the rest of the infrastructure.
Now you might be wondering: how was the DiscoveryGuy approach so effective? I still don’t have a solid scientific answer here (does anyone, after all?), but my hunch is that LLMs can quickly pick up the strong connection between the path to a sink and the structure of the seed that needs to reach it. Ultimately, that’s exactly what a human would do when tasked with crafting an input to hit a specific location, but slower.
To conclude: don’t make the mistake of flagging this as “AI-slop”. Vulnerability research is evolving faster than I have ever seen in my career, and these techniques must be part of your appsec to stay ahead. DiscoveryGuy was a big wake-up call for getting fully on board with new tools! To avoid sounding like an old, angry guy yelling at clouds: “in my time, exploit-dev was done by staring at gdb sessions for hours!”.