
AIxCC
The AI Cyber Challenge (AIxCC) was a two-year-long competition striving to fuse cybersecurity and the emergent properties of Large Language Models (LLMs) to push the field to its limits, going beyond what was previously considered possible. The ask was straight-forward, the solution was not. Create a fully autonomous Cyber Reasoning System (CRS) capable of finding and remediating (patching) vulnerabilities in critical open-source software such as SQLite, Nginx, Jenkins CI/CD, etc. To fuel research and inspiration, DARPA and ARPA-H put $29.5 million on the table. The semifinals, held during DEFCON 32, saw 7 teams take home $2 million each! The finals this year promised even bigger rewards for the top three: $4 million, $3 million, and $1.5 million, respectively.
Team Shellphish, our team, was incredibly lucky to walk away with $2 million from the semifinals and fifth place in the final competition. Here, we take a technical deep dive into the bugs and issues that prevented our system from reaching its full potential.







ARTIPHISHELL Architecture
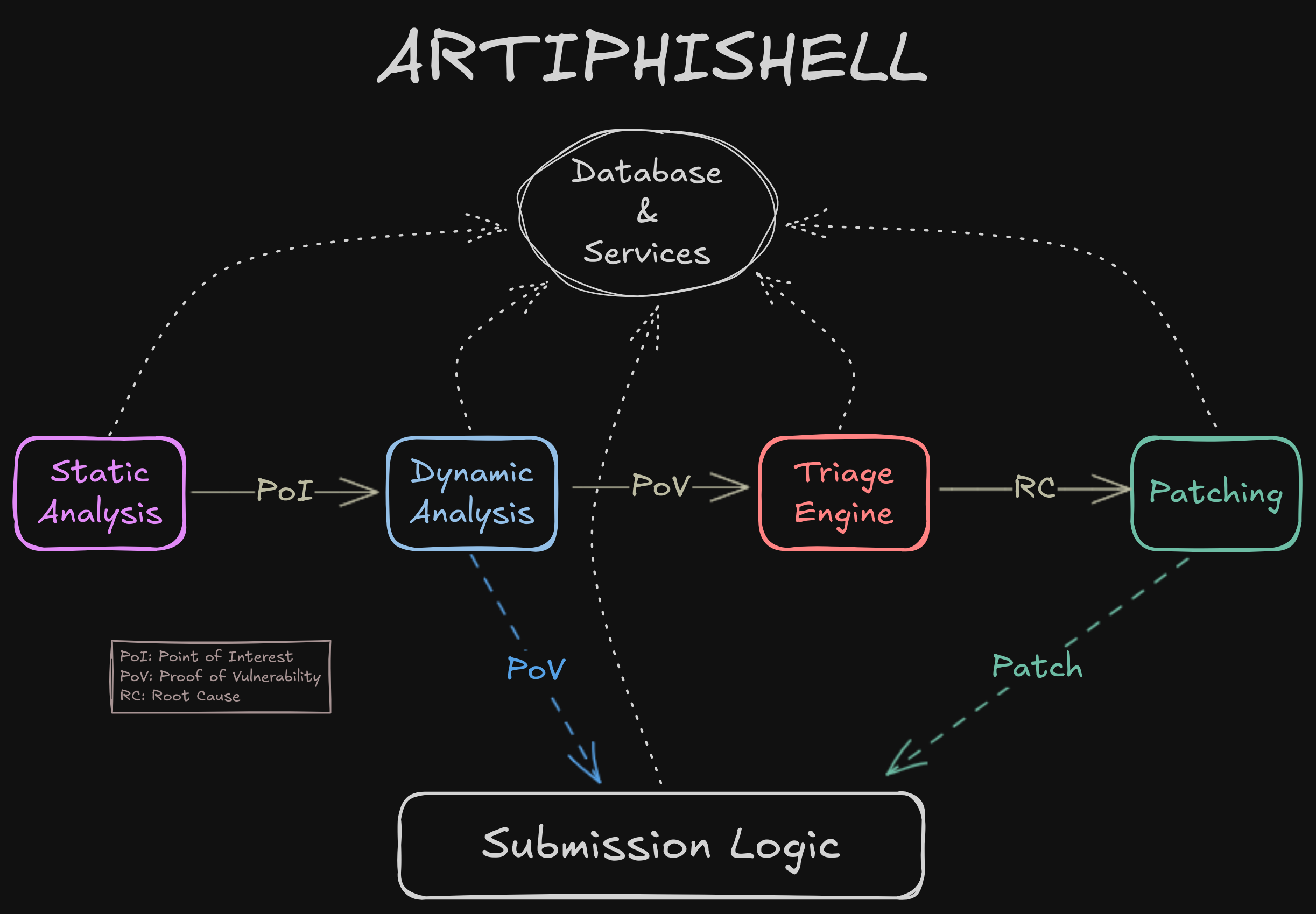
An oversimplification of our CRS, ARTIPHISHELL, comes down to four main phases, Static Analysis, Dynamic Analysis, Triage Engine, and Patching. Each phase depends on the prior phase to achieve some level of completion before being able to produce a result itself. Each of these phases is made up of many individual components with redundancy kept in mind. This allows us to at least hobble along in the worst-case scenario so that we can submit the bare minimum should a catastrophe arise.
While every phase is important, you’ll see here that Dynamic Analysis and Patching generate PoVs (Proof of Vulnerability) and Patches, respectively. These are the two main ways of scoring points in the competition (complicated scoring logic aside). Ultimately it boils down to: can you submit unique PoVs (crashes) that describe a single bug, and can you patch (mostly completely) that vulnerability? There are penalties for submitting duplicate PoVs and Patches for a single bug, incentivising accurate submissions.
When we receive a new vulnerability or patch that our system discovers, it is up to our submission logic component to determine which PoV and which Patch to submit. Choosing the correct PoV is not terribly difficult, but choosing the correct patch is not so easy. When you have multiple patches for a single bug that each cover X% of known crashes for that bug, but there’s not a single patch that covers all known crashes for that bug, you start to need complex scoring logic.
Finally, we have a litany of services that any component from any phase can call out to, such as building, testing, running PoVs, and retrieving information about a codebase (such as function and file names given a line of code). Most of these are non-critical and easily recover from any issues, but not all of them (as we’ll see later).
Post Mortem

Shellphish placed 5th at DARPA AIxCC finals 👀
After two years of intense development and cutting-edge research in automated vulnerability identification and remediation, we cannot deny that we had hoped for a higher ranking. Still, what truly matters is the impact of the ideas, tools, and innovations we pushed forward.
Before starting, kudos to Team Atlanta, Trail of Bits, and Theori for reaching this well-deserved milestone, a truly historic achievement! 👏🏼
That said, our team wanted answers.
What went sideways in the finals? Was this truly the best that Artiphishell could muster at full throttle, or did we once again get sabotaged by those all-too-familiar infrastructure bugs?
This isn’t just idle curiosity but a key question if we want to separate the techniques that genuinely delivered from the ones that flopped, and to figure out what lessons are worth carrying forward.
⚠️ Spoiler alert: Yes, we expected a few hiccups. No, we didn’t expect this many hiccups.
In the following, we’ll walk through the main technical culprits behind why our performance landed closer to “meh” rather than “marvelous.”
The 7 ARTIPHISHELL Sins
[1] 🎭 The Grammar-familiy tragedy
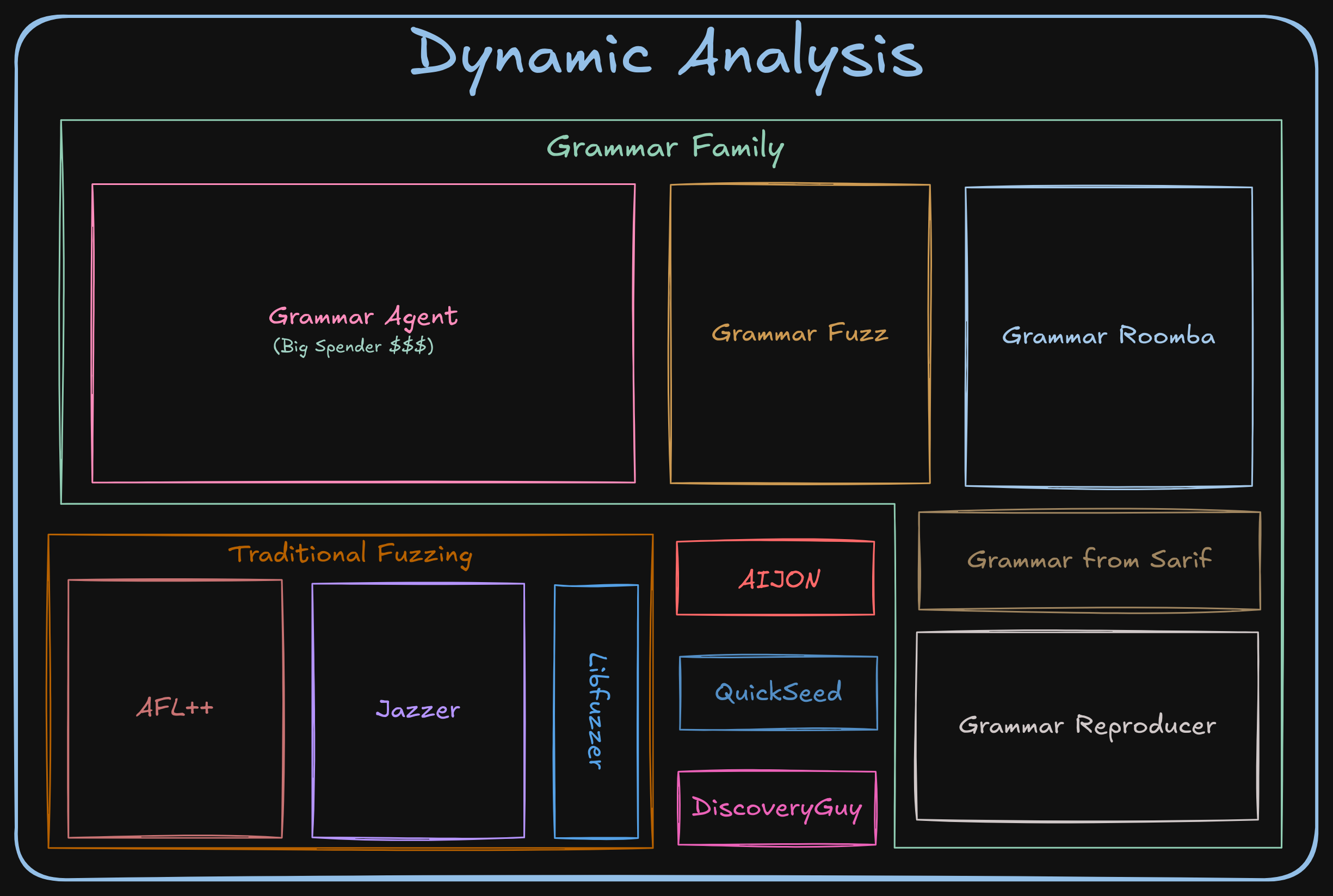
You’ve probably heard the rumors: Shellphish had a so-called “secret weapon” that promised a breakthrough in project coverage. The idea? Use LLMs to auto-generate grammars, giving us beautifully structured inputs that could dive deeper into the codebase than anything else we’d tried. And in pre-finals experiments, it really worked: Suddenly, we were exploring code paths that had never seen the light of day!
The catch?
This weapon wasn’t just powerful; it was expensive.
In one test run, it alone racked up nearly $10,000.
But hey, we had $50,000 in LLM credits to use, so we figured: why not? For the finals, we went all in allocating a big budget that let us unleash multiple of these grammar beasts in parallel.
Of course, we had to tread carefully.
These grammar beasts weren’t just pricey; they were also speed demons when it came to firing off LLM requests.
They were so fast that we consistently hit rate limits in the third exhibition round.
Consequently, we were worried this might throttle them into uselessness, especially because every instance was pounding on the Claude Anthropic API (since that showed the best results in our testing).
The grammar family of components made up much of our actual dynamic testing capabilities and was robust.
So robust, that many subsequent components relied on it to function properly.
However, to hedge our bets, in the final days of development (never a good phrase), we switched some of the agents over to other LLM providers to alleviate the rate limits with a new budget class called grammar-openai-budget inside our LiteLLM instance.
Unfortunately, a critical oversight during this last-second switch ended up throwing away all our efforts spent on developing these components…
The oversight?
We accidentally hardcoded the budget name of ALL the instances to be grammar-openai-budget.
This effectively prematurely killed ALL the Claude instances.
Annoying, sure, but maybe not catastrophic? …after all, we still had some of the instances running on OpenAI, right…?
…right?!
Well, misfortune loves company, and it turns out grammar-openai-budget was erroneously configured with a staggering maximum of $10 for the ENTIRE competition. Our secret weapon spent finals sitting quietly in the corner waiting for a turn to shine that never came.
Lesson Learned — Don’t wait until the night before to edit and test game-time configurations. Give yourself ample time to check and re-check the values.
[2] 🥳🛑 No grammar-agents, no party.
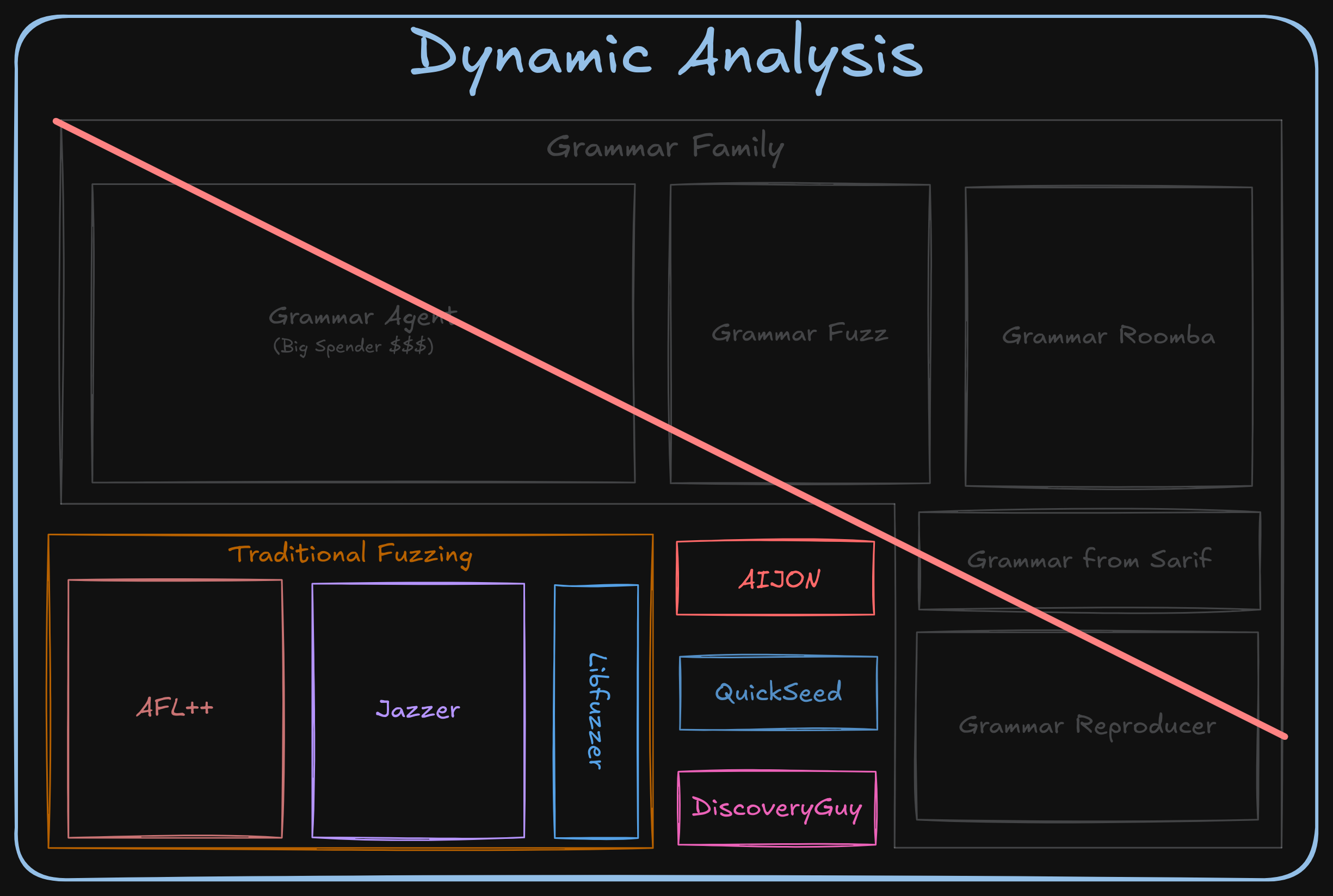
The fact that our grammar-agent component was basically yelling about being “out of budget” for the entire game caused a few unfortunate domino effects that disabled some other interesting tricks we had prepared.
To be more specific, we had a “grammar composition” component able to recognize nested input formats and create seeds that follow the identified structure (e.g., an HTML page containing a PNG).
In addition, our “grammar mutator” (for terminals and non-terminals) based on a custom version of Nautilus was knocked out of commission.
Finally, we also auto-generate token-level fuzzing grammars based on constants extracted from the LLM grammars to add more spice to our grammars.
As you can imagine, though, no grammar generated means no grammar party. Poof 🫥
Lesson Learned — Understanding and testing ALL potential failure cases is vital, as a single failure can unexpectedly knock down multiple components.
[3] 🂍🁃🁡 No grammar-agents, no party… Wait, again?!
Interestingly, one of the tasks of the grammar agent was to refine certain crashes coming from one of our custom versions of Jazzer (a Java fuzzer we employed during the competition).
🤨 What?
You may ask: Why the hell was this the task of a grammar agent?! Well, mainly, a lot of the code we needed for this refinement was already implemented in this component, so why not reuse it? 🍝
More specifically, we found that by loosening Jazzer’s off-the-shelf sanitizers, we could surface bugs faster.
For instance, take the Command Injection sanitizer: by default, it only flags cases where the magic string jazze makes its way into a java.lang.ProcessBuilder.
Our twist was: why not let it inject any even slightly invalid string? If we get an exception like Command not found from some nonsense input, we can toss that failure to an LLM, which then refines the seed and slips in the actual trigger string (jazze) where it belongs — neatly activating the sanitizer.
This trick proved to work VERY well in our experiments across different kinds of Jazzer’s sanitizers!

Sadly, if the LLMs on the other side are flat broke, then all this cleverness is wasted…
Lesson Learned — REALLY REALLY Understand and test ALL potential failure cases. (This budget failure is not something we ever encountered before in testing or practice rounds which is what hit us so hard)
[4] 🥖🛑 No submissions, no bread
What’s the mother of all fears when building a hands-off, fully automated, multi-million-dollar CRS? Doing all the work… and then failing to submit it for points.
Nightmare mode unlocked. It happened.
The component in charge of picking the best patch (i.e., patcherG) and passing it to the submitter had a little hiccup due to a spurious network error in an unexpected place and crashed. No big deal, right? We were ready for that — critical components are automatically restarted when they go down.
But then came a silly last-second “one-liner of doom” in its launcher:
/patcherg/scripts/run_patcherg.sh 2>&1 | tee -a "${TEMP_DIR}"/patcherg.log
This meant that whenever run_patcherg.sh crashed, the return code of the whole process came from tee… which happily always returns 0 (“everything’s fine!”). So the orchestrator never realized patcherG had faceplanted, and of course, never restarted it 🥲.
As a result, we generated working patches for the target dataharmonization…but never actually shipped them.
Lesson Learned — Create a rigid set of constraints for your orchestration system and then write a verifier (or have someone else) verify that EVERY component/command/etc. follows said constraint.
[5] 🐘🎪 Out-of-memory, out of business
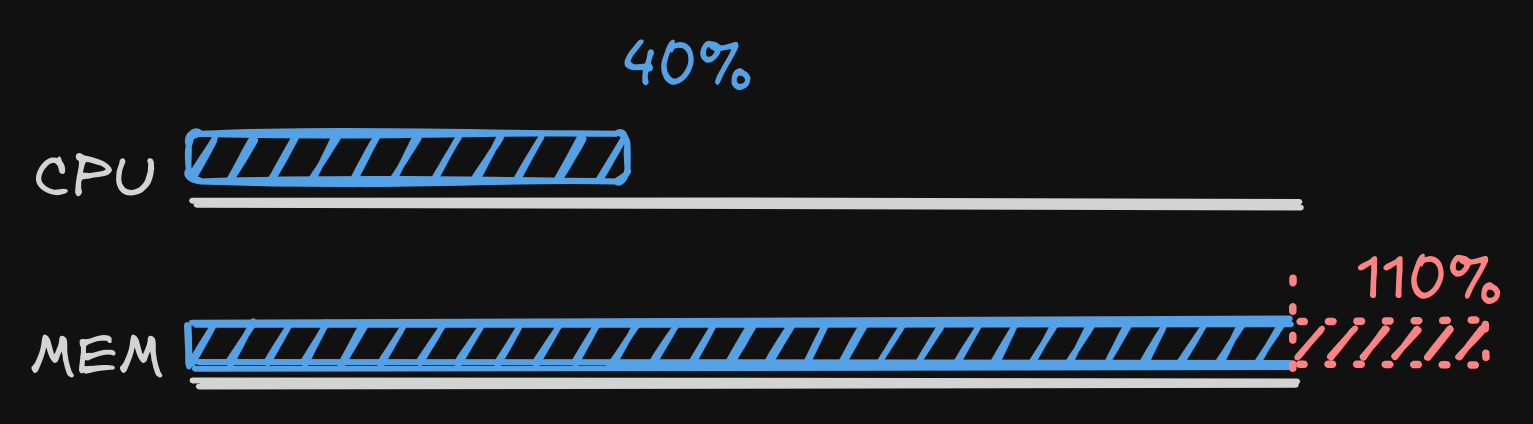
Despite all the testing we did before shipping our CRS, one challenge in the finals — wireshark — consistently blew up our build system with out-of-memory errors due to the 44 GB build artifacts. Every single time it showed up (seven times, each with a different vuln), our build system went down in flames, basically stopping any other actions for these tasks.
We later heard other teams ran into similar headaches, but for us this almost certainly dragged down our vulnerability count and contributed to our underperformance.
Lesson Learned — Always have a backup plan. We thought we had provisioned enough resources for any sane build, but didn’t account for insane builds. Planning for an ultimate failure case would have avoided this.
[6] 🫡 The function resolver: man down
The very first job of our CRS is to index the project. In practice, this means building a precise map of all the functions, their boundaries, and relevant metadata. This knowledge base then becomes the backbone for almost every other component in the CRS — whether it’s answering “which function does this line of code belong to?” or “show me all functions whose name contains the word copy.”
This “function resolver” is exposed as a RESTful service that every component can access. Different API endpoints implement different “questions” that can be asked of the function resolver.

The function resolver is initialized at the very beginning of the competition with the indexed artifacts of a given running challenge.
To speed things up and avoid recalculating the same data repeatedly, we relied on a cache. In testing, it behaved just fine. But during the finals, it went off the rails, growing until the service collapsed with out-of-memory errors.
This would have been fine (remember, critical services are supposed to restart!) … if only the service came back with its original data.
But no, we had been initializing it by storing the data inside the container instead of mounting it into the container. So every time the service restarted, it came back squeaky clean and empty.
Which meant that every component asking for function info was basically greeted with a nice “I have no idea what you are talking about, this thing is not initialized”.
This is very bad because it means every function lookup (whether for bug hunting, coverage feedback, or patching) suddenly became far less effective (if not outright useless). Fair to say, once the function resolver went down, the effectiveness of Artiphishell didn’t just dip, it pretty much fell off a cliff. LLM agents were unable to look up function code to analyze the target, triage was unable to identify crashing locations and the patchers could not retrieve function metadata for the targets where this happened.
This unfortunately happened a total of 20 times across the entire game, affecting multiple targets at different analysis stages.
Lesson Learned — If you rely critically on a server based application, ensure a local version is available in case of any mishaps.
[7] 🥶🎯 POV accuracy ruined for systemd
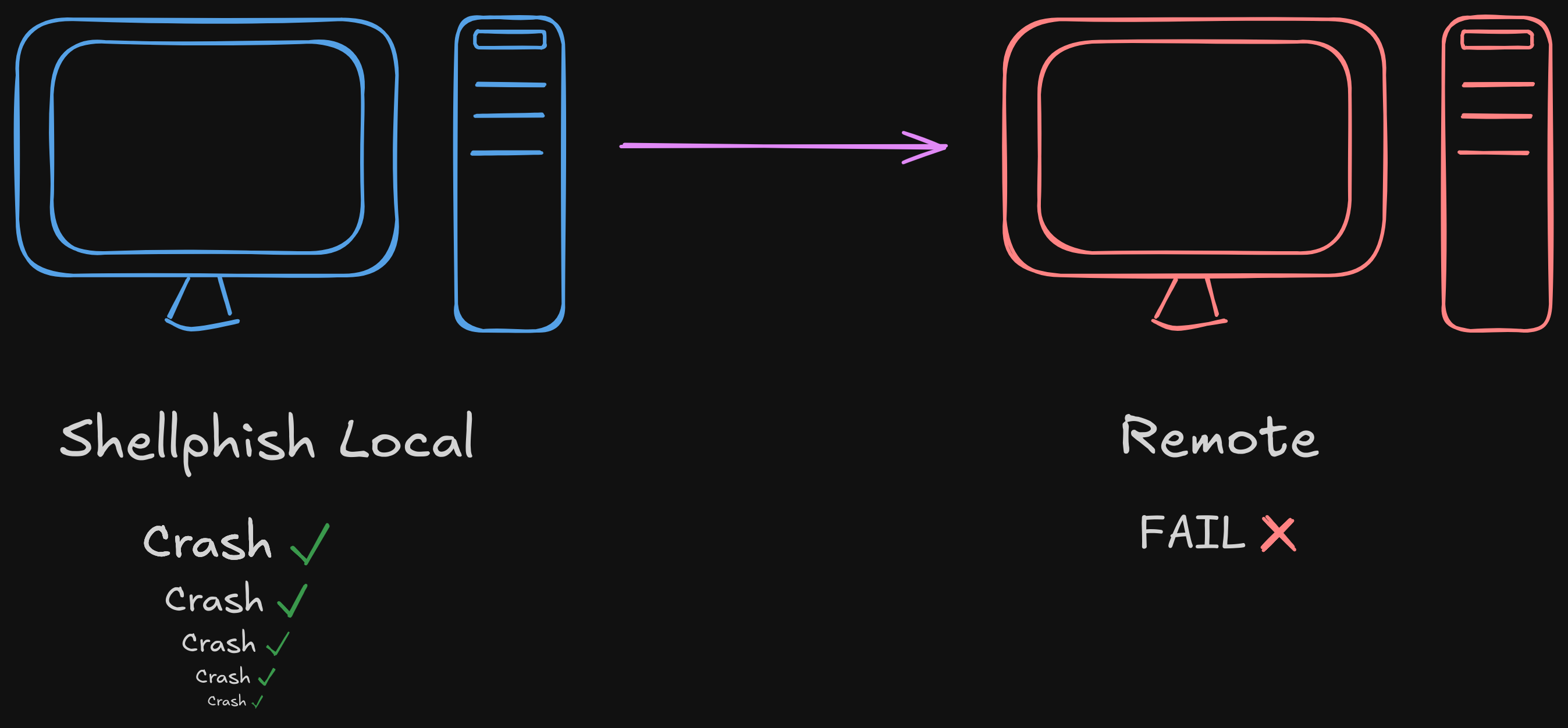
As you probably know, the first way to score points in AIxCC required CRS’s to submit Proofs of Vulnerability (POVs) that demonstrated the triggering of a sanitizer (ASAN, MEMSAN, or UBSAN) in a given challenge project for a given input. Any POVs that failed to reproduce on the organizer’s infrastructure caused the CRS to lose accuracy points, which in turn affected the overall final score.
When designing Artiphishell, we decided to only submit a POV if and only if a crash could be reproduced five times in a row.
That’s why it was a bit of a shock when, according to our logs, we ended up submitting a staggering 335 bad POVs (spread across 2-3 vulnerabilities) for the systemd challenge.
In other words: crashes we saw consistently on our side, but which stubbornly refused to crash on the organizer’s infrastructure.
We had seen a similar issue during the exhibition rounds on another challenge (SQLite). While triaging it with the organizers, we discovered that for certain MSAN-related crashes reproducibility depended on the CPU architecture (Intel vs AMD).
What went wrong this time is still unclear, but regardless, we see this as a minor factor behind our overall performance, especially since it luckily only impacted the score of this one target due to the way the accuracy multiplier is applied.
Lesson Learned — It may be worthwhile to keep at least one machine around capable of validating the exact organizer setup, down to the CPU.
Conclusions
As you can imagine, these 7 issues were responsible for our overall unsatisfying performance during the finals competition.
It is actually quite interesting to see that even with these HUGE problems, we managed to find 28 injected bugs, 11 patches, 7 0days, and had the most accurate patching system among all the CRSes, which we think is pretty cool!
To conclude, what can we learn from this story? Well, even with our best efforts at enforcing sound engineering practices, handling a team of ~30 researchers (with other academic responsibilities) in building a massive system is VERY hard.
While our pipeline’s design is built around the concept of isolated development, the reality is that a single (seemingly small) change can cascade downstream and break critical components.
And when deadlines get tight and sleep hours get short, one tiny mistake can unfortunately wipe out months of hard work.
That said, we’re genuinely excited about what we’ve contributed to the infosec community: the technology, the lessons learned, the excitement about applied AI in cybersecurity, and the techniques we’ll be sharing in the coming weeks. We’re just as eager to patch up what needs fixing, run further experiments, and keep pushing this system forward — to uncover more 0days, fix more software, and drive new breakthroughs.

Never stop hacking! 😎
~Shellphish